FLAT
Feedforward Latent Triangle Splatting for geometrically accurate scene generation.
Decode explicit surface-aligned triangle splats from video diffusion latents in a single forward pass.
1 Google Research
2 University of Oxford, Visual Geometry Group
3 Technical University of Munich
FLAT shows that compressed video diffusion latents can be mapped directly to explicit non-volumetric scene parameters. Instead of decoding 3D Gaussians, it predicts triangle splats in one pass, improving geometric accuracy while preserving competitive visual quality and enabling rasterization with simple triangle renderers and physics-based interaction after lightweight refinement.
How FLAT turns video priors into scene geometry.
FLAT reuses the information already encoded in video diffusion latents, then predicts triangle-based surface primitives that are easier to export, refine, and physically use than volumetric feedforward outputs.
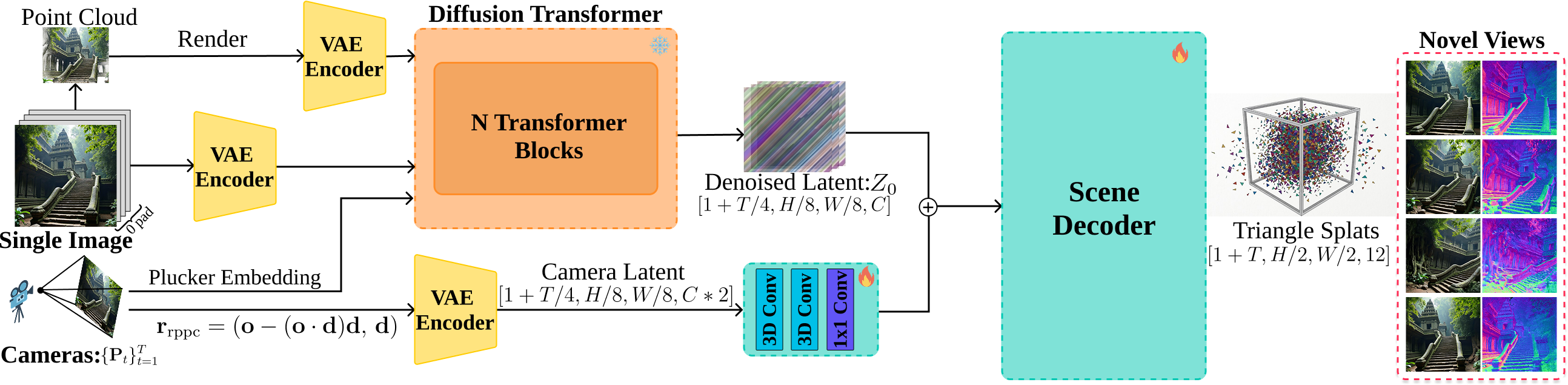
A camera-conditioned video prior provides multi-view latent structure, while FLAT adds a feedforward decoder that regresses explicit triangle splats instead of volumetric blobs.
Triangles are more sensitive to orientation than Gaussian primitives, so the method centers rotations around viewing rays and uses the product window function to keep differentiable rendering gradients usable.
The direct output is a triangle soup optimized for geometric fidelity. A small refinement stage then makes it opaque and easier to deploy in standard graphics and physics pipelines.
Inspect generated scenes as explicit triangle geometry.
FLAT outputs scenes that can be explored immediately with a simple triangle renderer. This makes the viewer fast and portable across devices, without depending on a heavy rendering engine. On touch devices, drag inside the scene to look around and use the on-screen movement buttons to navigate.
Pipeline Flexibility
FLAT is trained to decode denoised Wan-2.1 latents directly, so at inference time it can replace the standard VAE image decoder with a scene decoder. Any Wan-2.1 variant that is finetuned from base model can generate explicit triangle-based geometry instead of RGB frames.

FLAT does not require a separate generator for each video model variant. It plugs into the latent space of the base video model and changes only the final decode target from pixels to scene geometry.
Text-to-video, image-to-video, video-to-video, long-horizon, real-time, interactive, multi-conditioned, and world-consistent Wan-2.1 pipelines remain compatible as long as they produce the same denoised latent representation.
As the video-model family gains new controls or better generation quality, the same latent scene decoder can inherit those improvements without training a different scene model for every pipeline mode.
Appearance and surface structure stay aligned.
We target geometric accuracy, not only image realism. These paired renders show that FLAT's novel views and surface normals stay consistent across viewpoints, making the geometry signal legible instead of hiding it behind appearance alone.
Refined FLAT scenes support direct physical interaction.
Geometric accuracy and representation choice matter in practice: after converting the predicted triangles into an opaque asset, the generated environment can be used directly in a simple rigid-body simulation rather than relying on a separately reconstructed collision proxy.
@misc{kupyn2026flat,
title = {FLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation},
author = {Orest Kupyn and Goutam Bhat and Philipp Henzler and Fabian Manhardt and Christian Rupprecht and Federico Tombari},
year = {2026},
note = {Preprint}
}